阪大のスパコンSQUIDのGPUノード群でHorovod+TensorFlowを動かしました. 以前にNAISTのクラスタでもHorovodを動かしたのですが, やはり今回も一筋縄にはいかなかったので,手順をメモしておきます.
Pythonをインストールする
2024/12現在,SQUIDに導入されているPythonは3.6および3.8と古く,最新のパッケージを入れられないので Python 3.11をインストールします.ここでは新進気鋭?のパッケージマネージャである uvを用いてインストールします.
curl -LsSf https://astral.sh/uv/install.sh | sh
uv python install 3.11
venvを作成する
各種パッケージをインストールするためのvenvを作成します.SQUIDのhome領域は10GBしかないため,
色々パッケージをインストールするとすぐに溢れてしまいます.そのため,グループあたり5TB利用可能な
work領域 (/sqfs/work/(グループ名)/(利用者番号)) にvenvを作成します.以下はwork領域に作成した
ディレクトリで実行します.
uv venv --seed --python 3.11
source .venv/bin/activate
TensorFlowをインストールする
2024/12時点で最新のHorovod 0.28.1はTensorFlow 2.17.0以降と組み合わせるとコンパイルできませんでした. また,SQUIDにインストールされているCUDA 11.8とcuDNN 8.8と互換なTensorFlowのバージョンは こちらの表を見ると2.14.0であるため,これを インストールします.なお,このバージョンはNumPy 2.xと非互換なようなので,NumPy 1.xをインストール するように制約をかけます.
pip install tensorflow==2.14.1 "numpy<2"
Horovodをインストールする
Horovodをビルドしてインストールします. 基本的にGPUクラスタでの集団通信はMPIよりNCCLの方が速いらしいので, NCCLを有効にしてビルドします.
module load BaseGPU/2024
CC=gcc \
CXX=g++ \
HOROVOD_WITHOUT_GLOO=1 \
HOROVOD_WITH_MPI=1 \
HOROVOD_WITH_TENSORFLOW=1 \
HOROVOD_GPU_OPERATIONS=NCCL \
HOROVOD_NCCL_HOME=/system/apps/rhel8/gpu/nvhpc/nvhpc23.11/23.11/Linux_x86_64/23.11/comm_libs/nccl \
HOROVOD_NCCL_LINK=SHARED \
pip --no-cache-dir install horovod==0.28.1
それぞれの環境変数による設定の意図は以下の通りです:
CC=gccCXX=g++: BaseGPUをロードするとNVC/NVC++がデフォルトになるため,GCCを指定する.HOROVOD_WITH_MPI=1: MPIを必須にする.HOROVOD_GPU_OPERATIONS=NCCL: 集団通信にNCCLを使用する.HOROVOD_NCCL_HOME=...: NVHPC 23.11に同梱されているNCCLのパスを指定する.HOROVOD_NCCL_LINK=SHARED: NVHPC 23.11に同梱されている静的ライブラリlibnccl_static.aは CUDA 12.xのシンボルを参照している不具合? があるため,共有ライブラリlibnccl.soをリンクさせる.
ジョブを投入する
以上により環境を構築できたので,Horovodに同梱されているベンチマークスクリプト tensorflow2_synthetic_benchmark.py を動かして性能を測ります.以下は2ノード (16GPU) で実行する場合のジョブスクリプトです.
#!/bin/bash
#PBS -q SQUID
#PBS --group=...
#PBS -T openmpi
#PBS -l elapstim_req=00:10:00
#PBS -l cpunum_job=76
#PBS -l gpunum_job=8
#PBS -v LANG=C
#PBS -b 2
#PBS -v NQSV_MPI_MODULE=BaseGPU/2024
module load BaseGPU/2024
module load cudnn/8.8.1.3
cd ${PBS_O_WORKDIR}
source .venv/bin/activate
mpirun ${NQSV_MPIOPTS} \
-x LD_LIBRARY_PATH -x PATH \
-np 16 --map-by ppr:4:socket \
python3 tensorflow2_synthetic_benchmark.py --batch-size 256
SQUIDのGPUノードは,各CPUソケットにPCIeスイッチを介して4GPUずつぶら下がっている構成になっているので,
--map-by ppr:4:socketで各ソケットにつき4プロセス起動します.
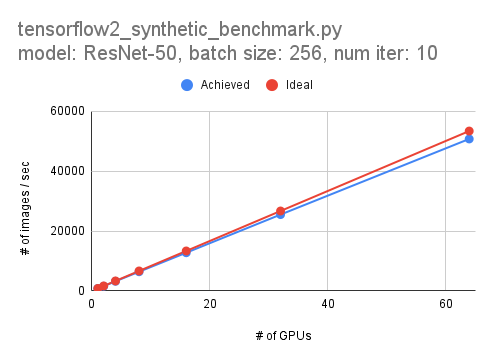
以下は1GPUから64GPUまで弱スケーリングした際の性能です. 1GPUで833.6 images/sec,8ノード (64GPU) で50,712 images/secとなりました. 64GPUで約95%の並列化効率なので,悪くはないのではないでしょうか.