NumpyやPandasライクなAPIで書いたPythonプログラムを簡単に並列分散化できる DaskをNAISTの小規模計算クラスタで動かしてみる.
インストール
まず,Dask本体と,Daskをジョブスケジューラと連携させるためのDask-jobqueueを インストールする.
$ pip3 install dask[complete]
$ pip3 install dask-jobqueue
クラスタの起動
次に,Dask-jobqueueを用いてDaskクラスタを起動する.
Daskクラスタはマスタ (dask-scheduler) とワーカ群 (dask-worker) からなる.
ここでは,ログインノード上にdask-scheduler,計算ノード (クラスタ
ノード) 上にdask-workerを配備する.
下記のコードをログインノード上で実行する.この際,カレントディレクトリは
計算ノードから見えるディレクトリ (/work/<ユーザ名>以下) でなければならない
ことに注意.
from dask_jobqueue import SGECluster
from dask.distributed import Client
cluster = SGECluster(cores=24,
memory="250GB",
queue="grid_short.q",
interface="ib0",
scheduler_options={"interface": "bond1"},
local_directory="/var/tmp",
job_extra=["-pe smp 24"])
# ワーカを10ノードで起動
cluster.scale(jobs=10)
client = Client(cluster)
InfiniBandを介して通信させるため,interface=ib0と指定する.
ただし,dask-schedulerを実行するログインノードは2つのInfiniBand HCAを
ボンディングしているため,scheduler_options={"interface": "bond1"}と指定する.
Daskはメモリに乗り切らない計算結果を自動的にディスクへ退避させる機能を
備えている.この際,並列ファイルシステムに書き出すと遅いので,
local_directory=/var/tmpにより,node-localなSSDを退避先として指定する.
cluster.adapt()を呼ぶことにより計算内容に応じて動的にワーカ数を増減させられる
はずだが,実際に動かしてみると下記のようなエラーが頻発し,ジョブの再実行が多発
して性能が劣化する.Daskのバグか使い方の問題かわからないので,
とりあえずcluster.scale()で静的にワーカ数を指定する.
distributed.worker - INFO - Can't find dependencies {<Task "('random_sample-sum-sum-19aeffb00e29595e523db6a2b1be622d', 35, 7, 0)" fetch>} for key ('
sum-19aeffb00e29595e523db6a2b1be622d', 35, 7, 0)
通信バックエンドはデフォルトでTCPを使用する.UCXを 使うこともできるようだが,検証していない.
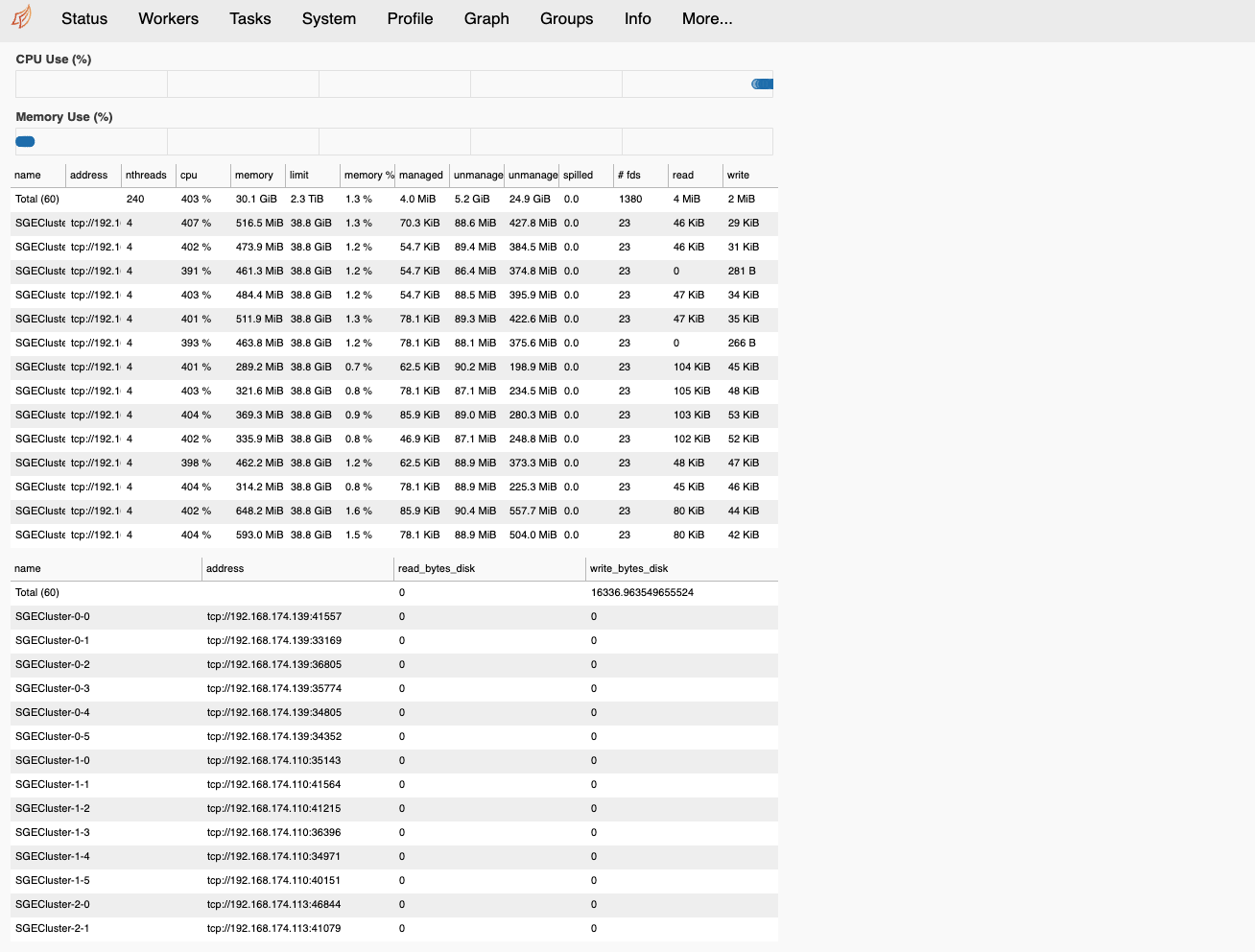
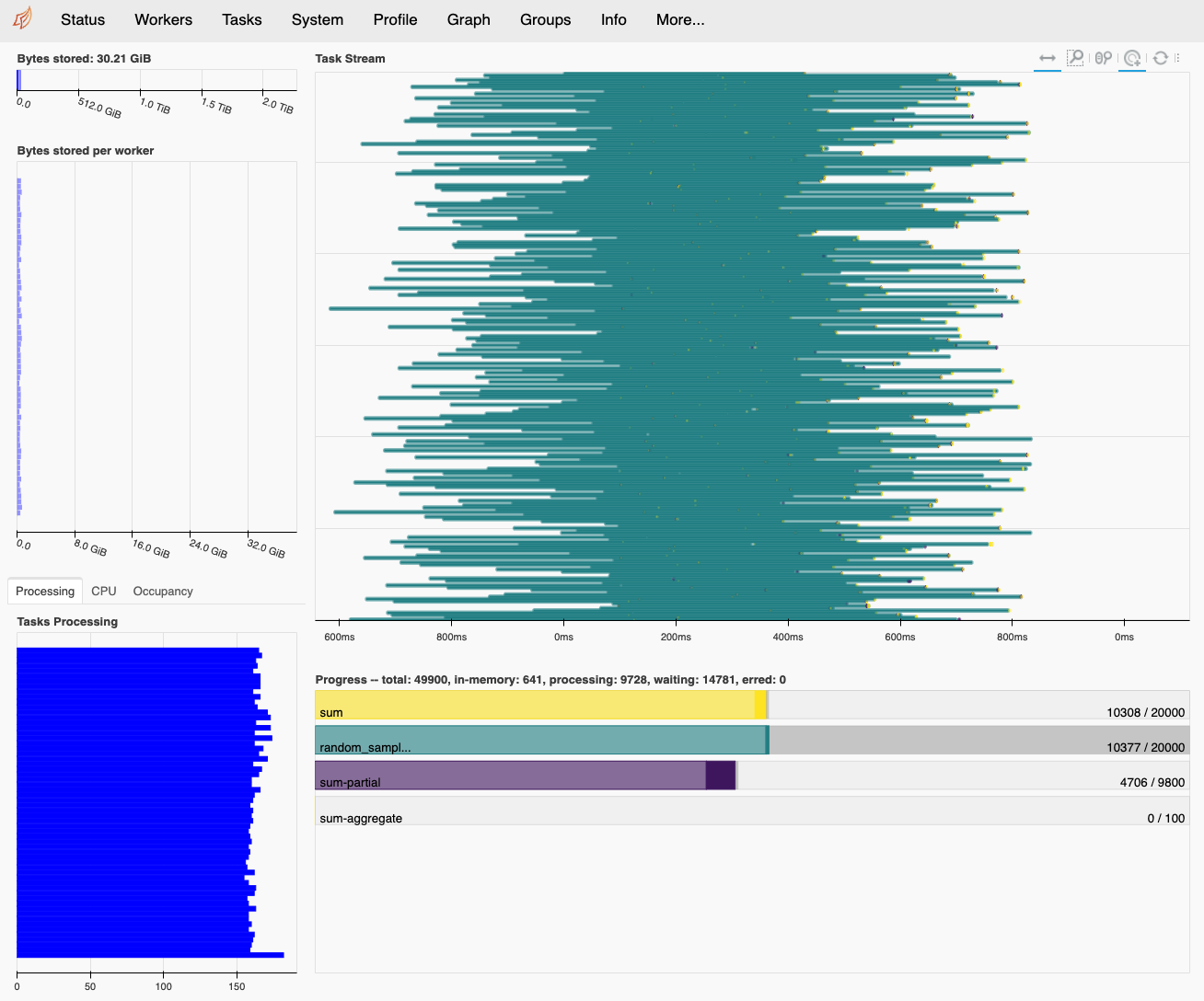
クラスタの状態の確認
http://<ログインノードのIP>:8787/statusをブラウザで開くと,ワーカの状態や,
計算の進行状況を確認することができる.
計算の実行
ログインノード上で下記のコードが正常に動けば成功
import dask.array as da
x = da.random.random((100000, 100000, 10), chunks=(1000, 1000, 5))
y = da.random.random((100000, 100000, 10), chunks=(1000, 1000, 5))
z = (da.arcsin(x) + da.arccos(y)).sum(axis=(1, 2))
z.compute()